Organising Source Code
A system for passing the dropbox test and improved source code workflow


My source code management has been a mess for ages. Not just through neglect but through lack of a system that is defined and evolved to meet my needs. My current system is a folder called 'code' that contains a lot of unsorted projects.
There is history of half baked attempts to sort this stuff out with folders named 'active' 'archive' 'play' and specific folders for client work but it's a mess to say the least.
The current size of this folder is 25GB and dates back to pretty much everything I have ever written, compilied locally, cloned or whatever. It is backed up all over the place, different computers, cloud storage, 2 x NAS devices and a USB key. None of these things are in sync, some are in source control, some aren't, the ones that are reside at github, gitlab, bitbucket and a private git server.
I used to pride myself on passing the dropbox test, which is a thing I remember from when dropbox used to go to members of the public and offer them a brand new mackbook pro if they would take their existing laptop from their bag and destroy it, right there and then. I don't feel like I would be able to pass the test now and would have to. decline which highlights the level of risk I am living with and not mitigating properly.
Structure
My initial thought was to create a stupidly ridiculous taxonamy that would be so difficut to memorise it would quickly become useless like the previous attempts. It would be 4-5 levels deep and provide a neat box for everything so I could find things quickly, because clearly I think I can search faster than a computer 😂.
After giving this some serious thought I decided to think about why I code, rather than what it is specifically and came up with a system I am enjoying using, it fits the current context I am in while I am coding:
- Kids - I make things with the kids, usually for the raspberry pi
- Home - I make things that automate the home, alexa skills, things like that
- PC - Personal Computing - code for managing photos, personal data, archiving tweets and all that kind of thing
- Company - I write code that my company uses
- Client - I do work for clients, this is the only level with a additional sublevel,
one per client name - Unsorted - More on this in a moment, but it's a place for things where I
don't yet know where to put them or if I am even keeping them
Syncronisation
I want to feel like I can pass the dropbox test which means making sure my code is synced elsewhere and enables me to get back up and running completely within minutes or hours - not days.
I quickly discounted cloud based services for keeping things in sync as I want more control. For a start I don't want everything syncing immediately, also things like node_modules, pycache and other dependencies I want to exlude by default.
RSYNC
It is a differential backup tool originally developed in 1996 that works on multiple platforms, it is brilliant at what it does and helps me keep my current layout and structure safely replicated elsewhere. No need to create a large backup file. I don't have to sync whole folders including their subfolders either. I send it over the wire and it's clever enough to detect only the blocks that have changed which means later syncs are fast, very fast. It even works over SSH but I use the rsync protocol as I connect to 'home' via VPN most of the time.
I now use the following command that sits in crontab and runs at midday every
weekday.
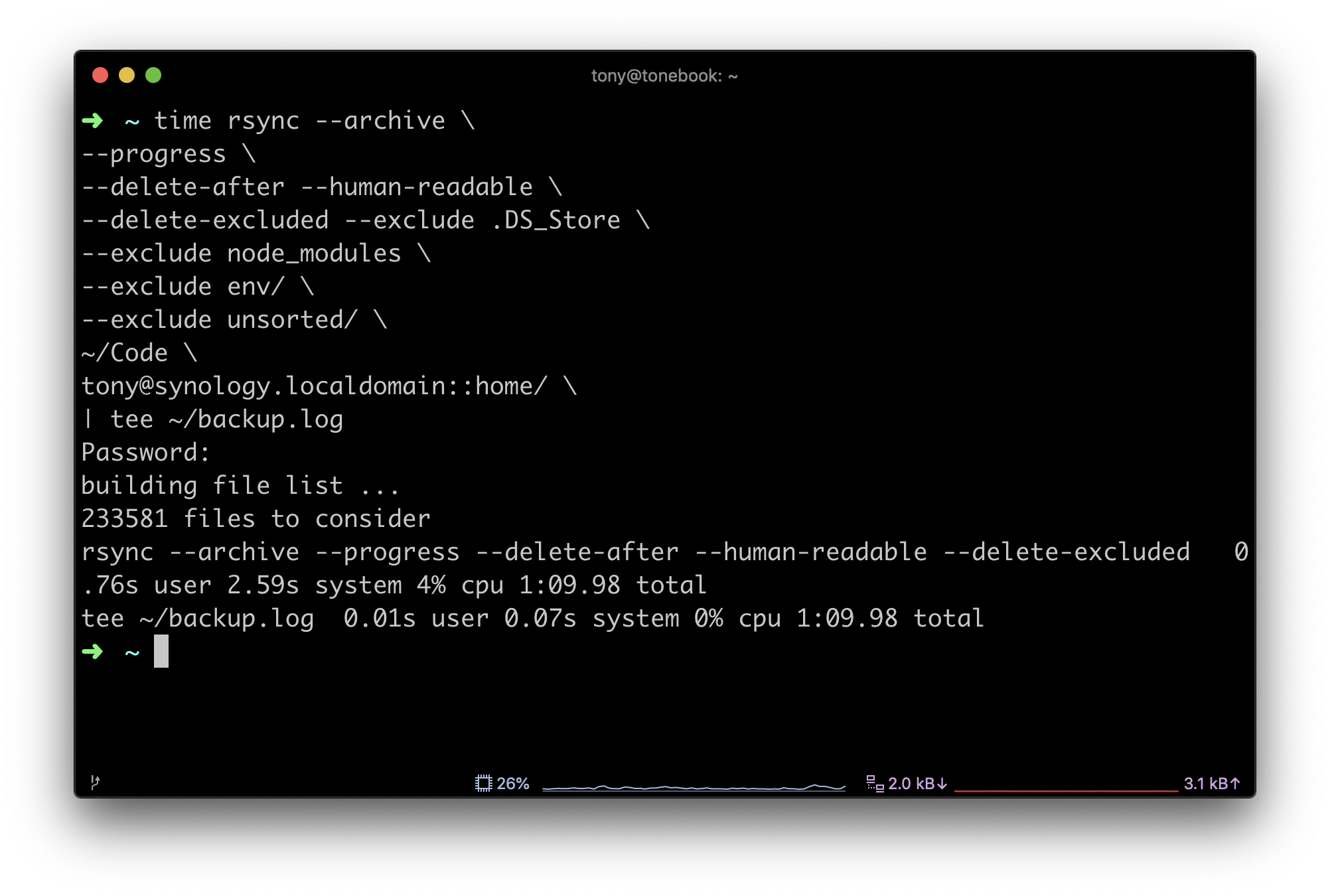
rsync --archive \ --progress \ --delete-after -- delete-excluded --human-readable \ --exclude .DS_Store \ --exclude node_modules \ --exclude env/ \ --exclude unsorted/ \ ~/Code \ [email protected]::home/ \ | tee ~/backup.log
If you want to emulate any of this, I strongly suggest you look at the man pages in particular the --delete options before trying this. I specifically want it to make the two folders the same and not a versioned history of the folders state. From my nas I do backup to the cloud using Spideroak, this gives me additional peace of mind and also versioning, also I am only backing up actual code, not all the dependeny libraries etc.
As you can see I exclude the things that don't need to be replicated and also the unsorted folder. This ensures I put things in the correct place quickly or it won't be backed up. This folder is essentially throw away, so if I have things in there I want to keep, I quickly categorise it in the correct folder.
I have since extended this to photo's, documents and other files and folders with slightly variying structures. If anyone wants to give me a brand new Macbook Pro (or even better a Surface Book 3) in exchange for trashing this one, get in touch, I can now pass the dropbox test.
I wrote this blog while prepping to rebuild my macbook pro without loosing anything and wanted to make it repeatable. My method has been working for over a month before I decided to go ahead with the rebuild. I am now totally confident in my own approach and I have extended this to all the computers we own.
References
